Ebook: Democratizing data access and use
Create the best data experiences and generate value across your ecosystem.
Discover our new ebook and learn all about data democratization.
[Webinar] Maximizing data value: How data products and marketplaces accelerate data consumption for business users
Register for the webinar
Put simply, data is facts or statistics collected together for reference and analysis. It can be numbers, text or a combination of both. Data is normally gathered to enable analysis or decision-making of some sort. This could be simple, such as counting the number of sales of a particular product, taking an electricity meter reading, or recording the names of employees. Alternatively it could be more complex, such as showing product sales by location or profitability of particular services.
This is where embracing open data unlocks the full potential of data. Open data is data which is openly accessible to all, including companies, citizens, the media, and consumers. Here are some popular open data definitions:
Data is considered open if it meets three key criteria:

Data must be easily available, such as online through an open data portal, in a convenient form, and in its entirety. It should make datasets free to access, with organizations only charging if they incur any reproduction costs (printing and posting information).

People accessing the data must be permitted to reuse and redistribute it, including combining it with other datasets. Depending on how it is licenced, there may be the obligation to attribute data to its source, and share any new datasets produced.

Open datasets must be equally available to all groups, whether private sector companies, individuals, researchers or public organizations. Everyone must be able to use, reuse and redistribute it, in easily understandable formats, for whatever purpose.
Clearly access to accurate, up-to-date data is vital to understanding what is happening within an organization, and for individuals looking to manage their daily lives. However, often this data is siloed and can only be accessed by specific groups within an organization. This means it doesn’t deliver its true value to all which is why they need to open it.
The term open data first appeared in 1995, related to the sharing of geophysical and environmental data. The concept was then codified in 2007, at a meeting of internet activists and thinkers in Sebastopol, California. It was based on principles from the open source movement and focused on the sharing of open data by public institutions. As the open data movement grew, countries around the world introduced legislation that mandated that data from public institutions (such as government departments, agencies, municipalities and other local government bodies) should be made available as open data. Examples of open data include:
This first wave of open data was followed by further rules and guidelines that extended open data requirements to other sectors, such as energy and utilities and public transport operators. We are now seeing an increasing number of private sector organizations, from banks and telecoms companies to industrial players making data open, due to the benefits it brings to their business, ecosystems and relationships with customers.

The public sector is mandated to share much of its data, either through regulations or because it is essential to democratic government and oversight. This is shared as open data, through channels such as websites, portals and apps.
However, open data can also be published and shared by private sector organizations, to increase engagement with stakeholders and to be transparent. An increasing number of companies, across multiple sectors are now sharing information as open data.
Therefore public sector data is always open data, but open data doesn’t have to be from the public sector.
Initially, the move to open data was driven by government legislation, and covered making data created by public bodies available to all. The rationale was clear. As taxpayers citizens funded these bodies, whether local municipalities or central government departments, they had the right to understand how they were performing through greater transparency. Regulations have now increased to cover other industries, particularly around areas such as meeting decarbonization and sustainability targets, especially in the energy and utility sectors.

From the 1970s, many European countries introduced Freedom of Information Acts, mandating that public sector bodies should both provide answers to questions submitted by citizens or organizations, and that people should be able to access the information held on them by public bodies. In France, the 1978 CADA law ensures public access to data and specifies the conditions for exercising these rights, while the UK Freedom of Information Act came into force on 1 January 2005.

The European Union first passed legislation on the reuse of public sector information in 2003, through Directive 2003/98/EC of the European Parliament. This set minimum requirements for EU member states regarding making public sector information available for reuse. It was subsequently revised to form the Public Sector Information (PSI) Directive in 2013 and then replaced by the Open Data Directive in 2019. This extended regulations to cover relevant data in the utility and transport sectors and research data resulting from public funding. Member states had until 16 July 2021 to transpose the new directive into national law.

Further relevant European legislation includes The Data Governance Act, published in 2020 and The Data Act, published in 2022. These acts aim to facilitate the access and reuse of industrial data, extending open data and positioning Europe at the forefront of a data-driven society. Thanks to this set of rules, the volume of data available for reuse will increase significantly and is expected to generate €270 billion in additional GDP by 2028.

One of the aims of the original 2007 Sebastopol meeting was to lobby for US federal legislation on open data. This came into force as the Open Government Directive in 2009. This mandated that federal agencies open their data, sharing it through the Data.gov portal. It was extended through the Open, Public, Electronic and Necessary (OPEN) Government Data Act, passed in 2019.
Legislation at a state level varies but all states now have their own open data portals, as well as Freedom of Information laws mandating transparency and information sharing. This means that there are a wide range of government open datasets available across the USA.
We live in a world powered by data. It is vital to how we live and work. By sharing vital information, open data empowers citizens, employees and organizations. It provides them with insight to make better, data-driven decisions while ensuring that they are fully-informed about the actions and activities of public and private sector organizations.
Open data delivers specific benefits in four key ways:

Sharing open data helps citizens and consumers better understand the workings and performance of public sector bodies and private companies. This increases engagement and drives greater trust. Making information available helps citizens to monitor public sector performance and provides consumers with data on areas such as company sustainability efforts, quality, and diversity in their workforce, for example.

Harnessing open data helps organizations become more innovative and data-driven. They can create completely new services and businesses, either to increase revenues or drive societal change. Additionally, organizations can improve decision-making by supplementing their own information to gain deeper insights. This improves efficiency, drives innovation and improves overall operations.

Sharing data across the public sector enables more joined-up, integrated government. It removes silos between organizations and ensures that decisions are made based on a complete picture of available information. It means that different parts of government do not have to collect their own data, improving their efficiency. And by making performance transparent and showing progress against objectives, organizations will be able to measure their success and focus their efforts on hitting targets.

Today people want to transparency, and open data helps give a complete picture. For example, by combining open data from different organizations municipalities can provide visitors with all the cultural information they need plan a trip. Bringing together data on environmental performance from different sources (such as air quality, transport emissions and energy efficiency) allows towns to measure their environmental impact. They can then take targeted actions to drive improvements.
Explore a range of compelling use cases around open data in our blog.
While the open data movement began in the public sector, and was initially driven by open government data acts, organizations in every sector can benefit by opening their data. In both regulated and non-regulated industries, sharing drives improved efficiency, better engagement with customers, citizens and employees, greater innovation through sharing new ideas/creating new services and increased collaboration between different players.
What types of data are different sectors sharing and what is the purpose behind their open data strategies? Looking at individual sectors, here are some examples of how open data is delivering benefits for organizations and their stakeholders

Municipalities face a number of challenges to create cost effective smart cities. They need to become more efficient operationally, improve their sustainability and above all provide the services and experiences that their increasingly tech-savvy citizens demand. Open data is vital to meeting all of these needs.
It is the fuel for smart city projects, with data sharing at the heart of new applications such as:

Government decision-making must be based on comprehensive, reliable data. It has to be accurate and shared easily between departments at both a state and federal level, in order to justify decision-making and to ensure that taxpayer dollars are spent efficiently and effectively. Collecting and analyzing multiple open datasets ensures that:

Energy and water utilities face multiple challenges around decarbonization, efficiency and meeting changing customer needs. Achieving this requires them to digitize their operations, break down silos between departments and build strong communities around their data to enable the shift to net zero. Implementing open data programs and increasing digitization ensures that utility companies can deliver:

Private sector companies are increasingly embracing open data. In many industries and regions new regulations (such as the EU Data Act) mandate that larger businesses open their data. Equally, innovative companies from across all sectors understand the benefits that open data delivers in terms of better communicating with stakeholders and customers while increasing transparency. Sharing data:
Given that open data is relatively new to many private sector companies, the range of use cases is likely to develop quickly over the coming years, as they embrace the benefits that it delivers.
Examples of leading open data portals in the private sector:
| Kering Environmental Profit & Loss Portal | KAPSARC |
| BPCE Group | SNCF Group |
| Infrabel | STIB |
| SBB | Swisscom |
Open data has to be reliable, structured and easily understandable by both humans and machines. People simply won’t use it if it is incomplete, poor quality, difficult to understand or lacks structure.
To ensure that open data meets the needs of users, organizations need to prepare their data.

Data quality is measured on metrics including accuracy, completeness, timeliness, consistency, and reliability. It is the foundation for successful data sharing – poor quality data will either not be used by stakeholders or will provide the wrong insights to decision-makers. Ensuring data quality is therefore a critical process and is essential to the success of open data programs. Data quality programs require organizations to:
These factors all need to be checked on a regular basis.

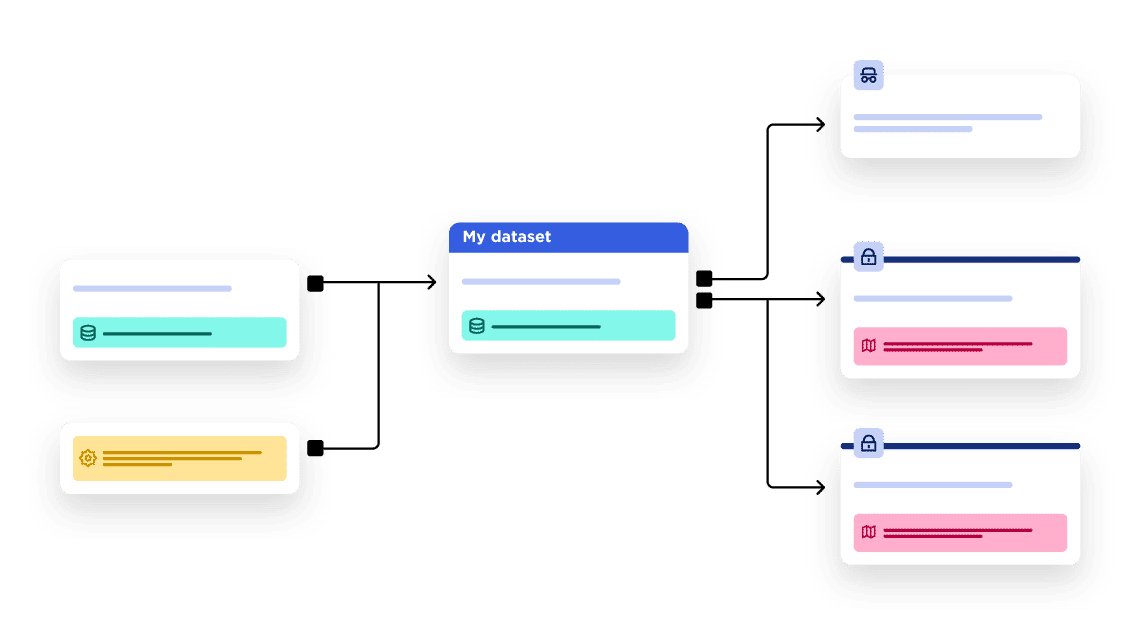
To deliver greater value from datasets they can be enriched with other information. This can come either from inside or outside the organization, adding data from official sources (such as government demographic or economic data), weather or from other organizations. These add context and make datasets more useful when sharing.
Types of dataset used to enrich data include:
The Opendatasoft Data hub offers over 30,000 freely available datasets that can be used to enrich open data.

Data management should be a clear process involved in preparing open data for publication. Organizations should establish an end-to-end methodology that covers all the different steps involved in data management, from preparation to end use, including data integration for their open data initiatives.
The process should include:
Tools are available to automate many of these processes in order to save time, while still ensuring consistency.

Data without context or structure is meaningless. Metadata helps provide that context. Essentially metadata is data that describes other data – it aims to create a context for your data by answering the basic questions: who, what, where, when, how and why? Metadata makes it easy for humans and technology tools to understand what your data covers, and the format is in by providing a summary of its content. Good metadata management is vital to open data success. First organizations need to establish a classification scheme for their data, creating a common vocabulary that describes data. This has to be clear and understandable by all, whatever their technical knowledge.
To help, there are a number of standardized models available, such as the ISO standard, Data Catalog Vocabulary (DCAT-AP) metadata standard or the Dublin Core Metadata Initiative (DCIM). For example, the ISO 8601 standard provides universal date formats. Metadata standards then need to be shared and enforced across the organization.
Once organizations have prepared their data they then need to publish it, making it freely available to the world. This requires a focus on three key areas:

Open data can broadly be licensed in one of three ways:
Organizations can create their own licenses for their open data. However, it is easier to use an existing, proven legal license. These include Creative Commons Licenses and those from the Open Data Commons. There may also be country/sector specific licenses that can be used – for example the UK Government mandates that UK government departments and bodies use the Open Government Licence. All of these licenses offer the same three levels (public domain, attribution, and attribution/share-alike) of legal protection.

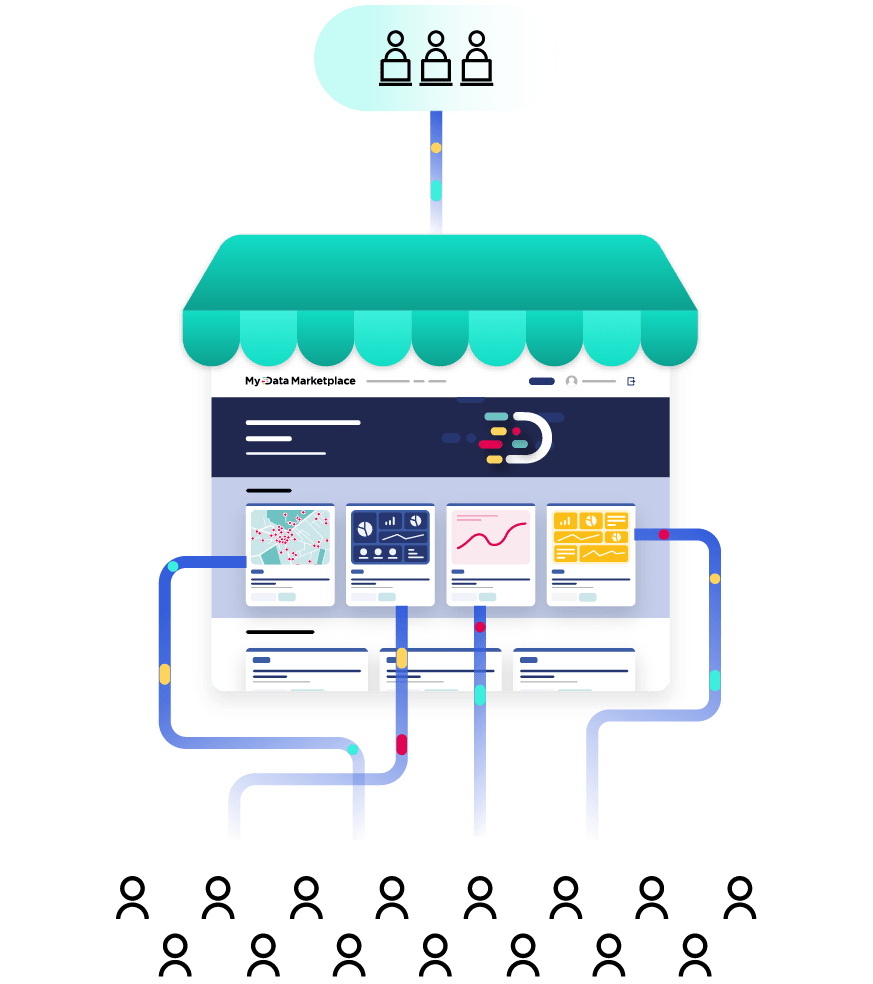
While data specialists may be happy to carry out open data analysis on raw datasets stored in a database or spreadsheet, citizens, consumers or other non-specialists are likely to find it easier to understand and act on data if it is in a more visual form. This requires organizations to create compelling data visualizations from their datasets. These could be zoomable maps or graphics, or as data stories, which combine text and images to explain its meaning.

Accessibility is one of three key criteria of open data. That means data should be freely available online. This can be through a specific open data portal, that collects and shares all of an organization’s open data, and/or via the corporate website. For example, some organizations might republish open data on specific pages of their main website, such as around CSR or other performance metrics. To maximize sharing, organizations should also ensure their data is available through open data hubs, with search features to facilitate discoverability and reuse.
The goal behind publishing open data is to help and inform key stakeholders, including citizens and consumers. Therefore once you have ensured data quality and published the data in the right places, it is vital to make it as easy as possible to reuse open data. This relies on two factors:

Is the data frequently updated? Clearly, publishing open data has a cost to the organization, as it has to collect, clean and share information, at no cost to the user. Therefore organizations need to put in place secure, stable budgets to ensure that open datasets are always up-to-date. Having a continuous history of a particular dataset (for example, dating back multiple years), makes it much more useful as key conclusions around changes over time can be made. Tools are available to automate updates to maximize the value open data delivers, while minimizing time and open data resources.

While all types of data can be shared as open data, it is most likely to be reused if it is in formats that can be easily understood and accessed by others. Being able to save data in open formats, such as a text file or .CSV spreadsheet file means it can be automatically accessed and reused by all.

As well as making data available via visualizations, and downloads many users (particularly data analysts) will want to be able to automate access to data, such as via APIs. This allows users to link datasets to their own systems and ensure that any updates automatically flow into their solution. It also makes it easy to download bulk data for detailed analysis. Offering APIs also enables AI and machine learning tools to automatically access and download data, without requiring human intervention.
Understanding how open data is used – and which datasets are most popular – is vital to success. That requires organizations to learn which data users find most useful, so that these datasets can be prioritized. Talking to users and gaining their feedback is a good way to begin to prioritize.
It is also possible to ask users to register, without charge, to access more methods of downloading or manipulating data. This does provide a guide to which datasets are delivering the greatest value. However, it can put off casual users who only wish to focus on accessing basic information.
Most open data platforms now provide full statistics and lineage capabilities on how many times a specific dataset has been accessed within an open data repository, and/or downloaded through APIs and other methods. This helps to gauge popularity, even if it doesn’t help to understand exactly what it is being used for. Following up with users can help to bridge this gap, and explain why particular open datasets are being used, and by whom. Resources can then be focused on similar data that might also be useful moving forward.
Opening data might look simple. However, data is often stored in multiple systems across an organization, may be described using different language and vocabulary, and be controlled by different departments. This means that collecting and sharing multiple datasets, while ensuring they are reliable, high-quality and current, quickly becomes a major initiative, potentially requiring significant resources. Success requires a focus on three key areas:

Data governance covers how an organization handles and uses the data it collects. It goes beyond open data, but given the importance of data to every organization, strong governance is vital. However, it is not straightforward, given the number of datasets generated by an organization, the different formats they are in, and the potentially hundreds of locations where they are stored. Managing all of this data so that it is readily available, high-quality and relevant is vital.
Data governance helps ensure that data is:
Data governance is also about putting in place the right human organization, structure and processes to move towards a data-driven model. This should include appointing data stewards responsible for each dataset, having clear processes that everyone follows, and ensuring sufficient monitoring so that all staff follow the governance framework. Read our blog for an introduction to data governance.

Organizations are used to working in silos, and keeping their data within their own team. Therefore, many departments, and entire organizations, may be risk-averse and worry that the data they share will be misused or misinterpreted. They may be worried that it opens them up to potential criticism in the case of public bodies. However, the benefits outweigh these risks – and in many cases openness is now mandated by regulations. Changing this approach requires changing organizations culture. Successful open data programs require everyone in the organization to understand the value and importance of data, and be committed to sharing it.
This means organizations need to create a data culture, which spans all departments and offices. This requires greater collaboration, both around data governance, but also to help develop data skills across the organization and make it as easy as possible to understand and share data. Training programs, education and strong communication, led from the top need to be put in place to create data advocates across the organization.

Technology is the third key to launching an open data project. Despite the fact that many organizations have spent large sums of money on their data infrastructure, information is still often locked away in silos, and only accessible by data experts. For open data projects to succeed, the right technology must be in place to gather, organize and share data. It must be simple to connect all data sources across the organization, enrich/clean data and then share it in compelling ways.
That requires an all-in-one platform that fits into and supports the organization’s data governance strategy and supports the growth of a data culture by being easy to understand and use. Open data has to be available in a variety of different ways, from visualizations such as maps and data stories to API downloads. Data search tools should help visitors easily find relevant data sets to use. Finally it has to automate the management and updating of datasets, removing overhead and making administration less-resource intensive.
Being able to combine datasets from different open data sources delivers additional value and increases innovation. Bringing together linked open datasets can unlock new insights and allow organizations to view their own data in new ways.
That’s why there are an increasing number of open data hubs that have been created to bring the open data catalogs of different organizations together. Being part of well-known data hubs also increases the chances of open data being found and reused, helping to increase uptake.
Many data hubs cover specific countries or industries – for example, the majority of countries and regions have their own data hubs for public data, including:

To help organizations and individuals maximize the value of open data, Opendatasoft has created its own data portal. The Opendatasoft Data hub contains over 29,000 open datasets from private and public organizations across the globe. It is designed to make it as simple as possible for everyone to access, understand, combine and gain benefit from open data. For example, it features 600 reference datasets created by official data producers, open data companies, and authorities, such as USAC open data and World Bank open data. These are organized in different thematic packs, such as geographic, demographic, economic, housing, or work-related datasets. Examples include a complete database of US Zip codes, and records of global weather dating back to 2015.
The Opendatasoft Data hub also comes complete with a full range of tools to aid reuse, from visualizations to bulk downloads. Users can simply click on one or more datasets, combine them and then create maps or charts. Being able to bring together diverse datasets in this way, enriched with powerful reference data, enables new innovative data uses by all.
Learn more about the Opendatasoft Data hub in our in-depth blog.

Open data sharing is a process of continual improvement. Organizations understand that there is always more data that they can be sharing, new ways of making it available in order to better engage with stakeholders, and innovative methods of combining it with other datasets to increase value.
That is why studies measure the open data maturity of countries and organizations. This provides the ability to compare leaders with those that are earlier in their journeys, and enables everyone to learn from best practice and follow the latest trends.
The most prominent international study is the European Commission’s Open Data Maturity report. This annual study assesses how 35 European countries are approaching open data, measuring progress against four key criteria (national policy, impact of open data in the country, the strength of its open data portal and the quality of the data/metadata within it). There’s more on the 2022 edition of the report in this in-depth blog.
Equally a range of non-profit organizations have developed tools and frameworks to help increase open data sharing maturity. For example, the Open Data Institute has created its Open Data Maturity Model, which helps organizations to assess how well they publish and consume open data, and identifies actions for improvement. This model has been applied by organizations around the world. Additionally, many state and government level bodies have created maturity models that can be used by their affiliated agencies, such as the DC Data Maturity Model, created by the District of Columbia.

Create the best data experiences and generate value across your ecosystem.
Discover our new ebook and learn all about data democratization.