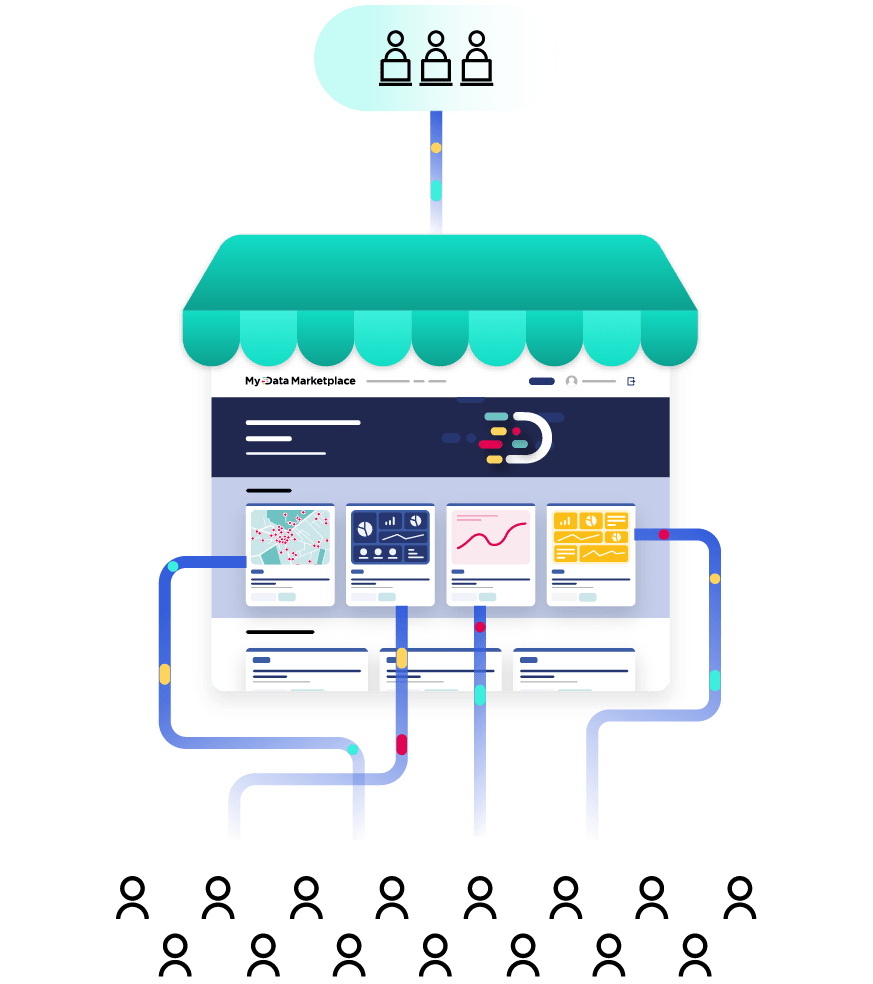
It is also possible to ask users to register, without charge, to access more methods of downloading or manipulating data. This does provide a guide to which datasets are delivering the greatest value. However, it can put off casual users who only wish to focus on accessing basic information.
Most open data platforms now provide full statistics and lineage capabilities on how many times a specific dataset has been accessed within an open data repository, and/or downloaded through APIs and other methods. This helps to gauge popularity, even if it doesn’t help to understand exactly what it is being used for. Following up with users can help to bridge this gap, and explain why particular open datasets are being used, and by whom. Resources can then be focused on similar data that might also be useful moving forward.
8. Governance, tools and culture: the 3 keys to launch your open data project
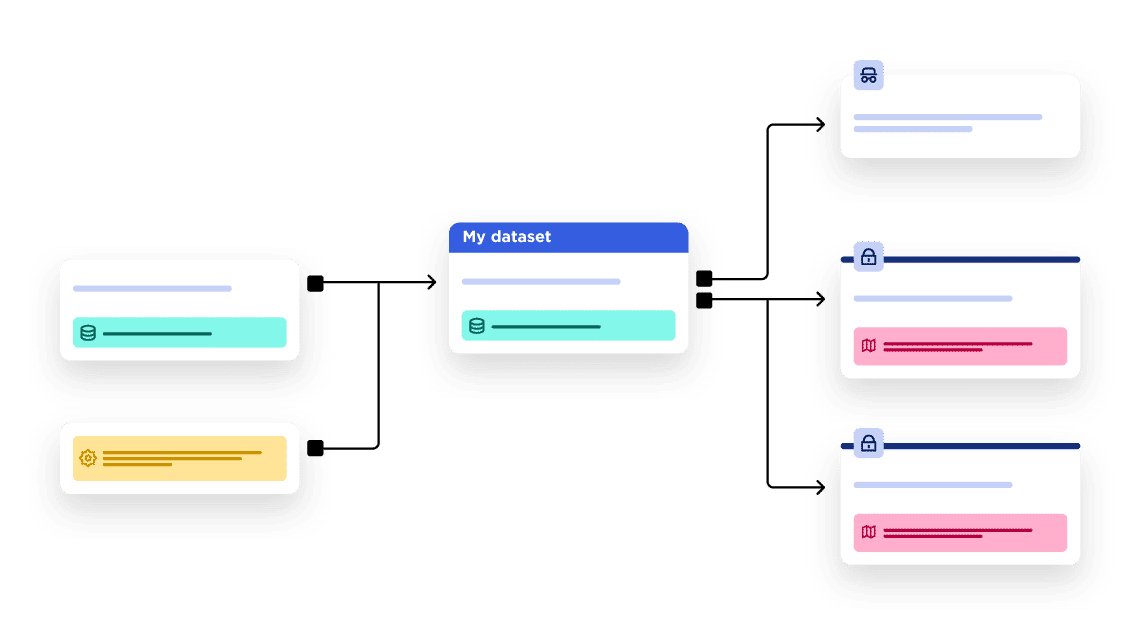
Opening data might look simple. However, data is often stored in multiple systems across an organization, may be described using different language and vocabulary, and be controlled by different departments. This means that collecting and sharing multiple datasets, while ensuring they are reliable, high-quality and current, quickly becomes a major initiative, potentially requiring significant resources. Success requires a focus on three key areas: